The Theory of Computation is concerned with asking fundamental questions such as:
In order to address the first two questions, we must start with the last one, that is, how to represent computation in forms that admit rigorous analysis and not merely execution.
In this module, we model computation using languages and machines, and we examine the close relationships betwen these forms of representation.
A language is typically defined as the set of words (strings containing the symbols in some alphabet).
The machines that we consider are those that compute by
The set of all words of the form: ambncm+n
where m and n range over all the natural numbers 0, 1, 2, ...
and xn denotes the string containing n successive copies
of the symbol x.
Here are some valid words in it:
and here are some words with the same alphabet but not in this language:
This language might be said to represent addition.
Similarly, the language containing all
words of the form ambncm-n
such as:
is a representation of subtraction.
Many other functions may be represented
in the form of a language.
A machine that accepts only words in Language 1, and rejects all others,
could be described as an addition acceptor.
Similarly, a machine that was capable of
accepting any string of the form ambn and
then producing the string cm+n, could be described
as an addition machine.
A vending machine supplies 30 products
(Mars bars etc.) and has a numeric keypad with the digits 0-9.
The machine works by accepting the input language (the vending code) and then
delivering the relevant product.
What code should we assign to each product?
If we assigned the numbers 1-30, then the machine would be unable to distinguish
the code 1 from the code 11.
This problem would be avoided if we were to use the numbers 10-39, each of which
has exactly two digits.
Language 2 belongs to the class of languages called regular, but Language 1 does not.
For every regular language, we can
construct an acceptor machine that belongs to the class of machines called
finite state automata.
No finite state automaton can be designed
to accept the languages of addition and subtraction.
They belong to the class of context free languages (a class that includes
most proramming languages).
To recognise a context free language requires the power of the class of machines
called push-down automata.
The regular languages are also recognisable by push-down automata, but even these machines are limited in their computational power, that is, in the class of languages they can recognise, or equivalently, the class of functions they can compute.
They cannot recognise the context sensitive
languages, which require the power of Turing Machines.
This class of machine is the most powerful.
In fact, no function that cannot be computed by a Turing Machine can be computed
at all!
A finite state automaton (FSA) consists of
For each symbol, there is exactly one transition
out of each state.
One state is the initial state in which the automaton starts.
Some states are designated as accepting states.
Any FSA may be represented by its transition diagram, a directed graph in which
[Note that the textbook uses a slightly different notation for transition diagrams in which the start state is represented by an unlabelled incoming arc and the accept states by double circles.]
Consider the following transition diagram:

The language recognised by this FSA has as its alphabet the symbols 0
and 1.
We can trace its behaviour when presented with a string of symbols from this
alphabet, say, 1010.
It starts in state 1 (note that the names of the states are not symbols
in the alphabet), reads the first symbol in the string (1) and follows
the arc out of state 1 that is labelled with that symbol, taking it to state
2.
It now reads the next symbol in the string (0) which takes it to state
3,then the next symbol (1) which takes it to state 4 and finally
the last symbol of the string (0) which takes it to state 0, which is
an accept state.
The string 1010 is therefore a word in the language recognised by tis
FSA.
Trace the behaviour of this FSA when presented with the string 01101.
You should find that after having read
the last symbol in this string, the FSA is not in an accept state.
The string 01101 is therefore not a word in the language recognised
by tis FSA.
Find some other words that are accepted
by this FSA.
Find some other words that are rejected by it.
Can you think of a property that is shared by all, and only, the strings accepted
by this FSA?
The set of all strings that share this property is the language recognised by
the FSA.
We will refer to this language as even-even.

Note that the state transition function need not be total, that is, there
may be some states in which not every input symbol occurs on an outgoing arc.
When an FSA is in such a state and inputs a symbol for which there is no outgoing
arc, it crashes and will not read any more symbols. Since it cannot arrive
at an accept state when it has exhausted the input string, it rejects all strings
whose prefix causes it to crash.
The language of Binary Integers comprises the following strings:
The FSA that recognises this language has the following values:
|
0 |
1 |
|
|
1 |
2 |
3 |
|
2 |
- |
- |
|
3 |
3 |
3 |
Self Assessment Questions
Here are some more examples:

In our definition of FSA, state transitions
are defined by a function, that is, at each state there is no more than
one outgoing arc for each symbol.
We can extend this to allow more than one outgoing arc from any state to be
labelled with the same symbol.
An input sequence is accepted by such a Non-deterministic Finite State Automaton
(NFSA) if any sequence of transitions, corresponding to the input sequence,
leads from the start state to an accept state.
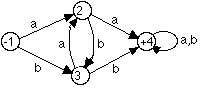
Here is a transition diagram for a NFSA:

Note that there are two outgoing arcs from state 1 labeled with the symbol 0.
The strings 01001 and 11001 are both accepted by this NFSA because
there are sequences of transitions that are labeled by 0,1,0,0,1 and
1,1,0,0,1 respectively.
The language recognised by this NFSA comprises all strings over the alphabet
{0,1} that contain either two successive 0s or two successive
1s.
The state transition function for this NFSA maps each state-symbol pair to a
set , that may be empty or singleton, of next states among which the
NFSA may freely choose.
|
0 |
1 |
|
|
1 |
{1,2} |
{1,4} |
|
2 |
{3} |
{} |
|
3 |
{3} |
{3} |
|
4 |
{} |
{5} |
|
5 |
{5} |
{5} |
A NFSA may also have arcs labeled with
the empty symbol, which we will denote by the letter e.
Note that this is not a symbol in the alphabet of the NFSA.
It labels a transition that the NFSA may make without reading the symbol
on its tape.
If a NFSA is in a state from which an arc labeled with the symbol leaves,
then it may choose, non-deterministically, to follow that arc to the
next state.
Here is an NFSA with such arcs.

What language is accepted by this NFSA.
Now it is obvious that every deterministic
FSA (DFSA) is representable as a NFSA. Simply reformulate its state transition
function so that the destination state becomes the singleton set containng that
state.
Therefore, every language recognisable by a DFSA is also recognisable by
a NFSA.
This means that the class of DFSAs is no more powerful than the class
of NFSAs.
However, is the converse true?
Is there any language recognisable by a
NFSA but not by any DFSA?
If this were the case, then the class of NFSAs would be more powerful than the
class of DFSAs.
In fact, two classes are strictly equivalent.
The proof of this proposition is by a constructive algorithm that converts
any NFSA, M, to its equivalent DFSA, M'.
The key idea is to view a NFSA as occupying, at any momonet, not a single state
but a set of states comprising all those than can be reached from the
initial state by means of the input consumed so far.
The set of states of M' with therefore be the powerset of Q,
the set of states of M, and the set of final states of M' will
consist of every subset of M that contains at least one final state of
M.
A move of M' on reading an input symbol imitates a move of M on
reading that symbol, possibly followed by any number of e-moves of M.
We define E(q) to be, for each state q in Q, the set
of states that can be reached from q without reading any input.
Then the transition function for M' is derived by calculating, for every
subset of Q, and for each symbol in the alphabet, the set of states that
can be reached form any member of the subset by reading that symbol and applying
E to the destination states.
The NFSA in Language 8 above may be transformed
to an equivalent DFSA as follows:
Forst, calculate E:
E(1) = {1,2,3,4}; E(2) = {2,3,4}; E(3) = {3}; E(4) = {4}; E(5) = {4,5}
Then construct the new state transition
table for M', indicating the start state with '-' and the accepting states
with '+':
| State | Symbol | New State |
| -{1,2,3,4} | a | {1,2,3,4,5} |
| -{1, 2,3,4} | b | {3,4,5} |
| +{3,4,5} | a | {4,5} |
| +{3,4,5} | b | {4,5} |
| +{4,5} | a | {4,5} |
| +{1,2,3,4,5} | a | {1,2,3,4,5} |
| +{1,2,3,4,5} | b | {3,4,5} |
which is clearly deterministic.
We can make a further extension to our
notation for FSAs that does not add to their power.
A Transition Graph (TG) is similar to a transition diagram but may have
the following additional attribute:
A TG may make a state transition along
such an arc if the string labelling that arc is a prefix of the current
input string.
If an arc from a state is labeled with the null string, then the TG in that
state may choose non-deterministically to make a state transition along
that arc.
Clearly, any arc of a TG that is labelled
by a non-empty string can be expanded into a sequence of transitions, one for
each symbol in the string.
Also, allowing the null string to label arcs is just another way of introducing
non-determinism, and therefore does not add power.
We conclude that the every laguage recognisable by a TG is also recognisable
by a FSA.
The two classes are strictly equivalent.
![]() Back
to Topic 1
Back
to Topic 1
![]() Next
Topic
Next
Topic
If you have comments or
suggestions, email to author at b.cohen@city.ac.uk
or me Vid-Com-Ram
/ members.tripod.com/bummerang
ËÁŇÂŕËµŘ : ŕ͡ĘŇĂŕǻ˹éŇąŐéąÓÁҨҡÁËŇÇÔ·ÂŇĹŃÂáËč§ËąÖč§ăą»ĂĐŕ·ČÍѧˇÄÉ
ŕ»çąËĹѡĘٵäĹéҤĹÖ§ˇŃş CT313 ąÓÁŇŕľ×čÍŕ»çąŕ͡ĘŇĂŕ»ĂŐÂşŕ·ŐÂşáĹĐÍéҧÍÔ§ ÁÔä´éËÇѧĽĹ»ĂĐâÂŞąěă´ć
áĹТͺ͡ÇčŇŕ¤éŇÁŐĹÔ˘ĘÔ·¸ÔěąĐ