บทที่ 7 การทำโมเดล
จุดประสงค์
1. เพื่อให้เข้าใจหน้าที่ของระบบว่า ระบบทำงานอะไรบ้าง ผู้ที่ต้องเข้าใจหน้าที่ของระบบได้แก่
นักวิเคราะห์ระบบ, เจ้าของงาน, User หรือโปรแกรมเมอร์ก็อาจต้องการรู้ในระดับหนึ่งเพื่อให้เห็นภาพรวมซึ่งจะทำให้เขียนโปรแกรมได้มีประสิทธิภาพมากยิ่งขึ้น
2. เพื่ออธิบายว่าระบบทั้งใหม่และเก่านั้นเป็นอย่างไร ถ้าเราต้องการอธิบายระบบในส่วนไหนเราก็เขียนในส่วนนั้นก็พอ
ซึ่งแบ่งออกเป็น 3 ส่วนใหญ่ๆคือ
2.1) External Perspectiveเป็นมุมมองภาพรวมของระบบ ว่าภายนอกของระบบมีการโต้ตอบกับระบบแวดล้อมอื่นๆยังไงบ้าง
หรือถ้าไม่มีระบบแวดล้อมอื่นๆเป็นระบบเดี่ยวมีการโต้ตอบกับ User ยังไง
2.2) Behavioural Perspective เป็นมุมมองที่เราจะสนใจพฤติกรรมของระบบ
ว่าระบบมีกระบวนการทำงานอย่างไรบ้าง มีการโต้ตอบกับสภาพแวดล้อมยังไง เช่น ถ้าสภาพแวดล้อมเปลี่ยนไประบบจะทำยังไง
2.3) Structural Perspective จะเน้นที่ข้อมูล , การจัดเก็บข้อมูล
, มีความสำคัญอย่างไร
Model ประเภทต่างๆ
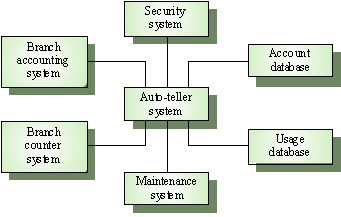 1. Context
Models ( จัดอยู่ในกลุ่มของ External )เน้นที่ขอบเขตของระบบ ( ไม่เน้นรายละเอียดของตัวระบบ
) มีการเชื่อมโยงระบบอื่นๆหรือUser ใดบ้างหรือกับขอบเขตภายนอกอะไรบ้าง
1. Context
Models ( จัดอยู่ในกลุ่มของ External )เน้นที่ขอบเขตของระบบ ( ไม่เน้นรายละเอียดของตัวระบบ
) มีการเชื่อมโยงระบบอื่นๆหรือUser ใดบ้างหรือกับขอบเขตภายนอกอะไรบ้าง
จากรูป <Slide 5> จะเป็นระบบ ATM ซึ่งเราจะสนใจระบบ ATM ตรงกลางเท่านั้น
ซึ่ง Context Diagram จะบอกว่าระบบ ATM จะเชื่อมโยงกับใครบ้าง ทั้งระบบบัญชีสาขา
, ระบบรักษาความปลอดภัย เป็นต้น
Context Diagram ที่เราคุ้นเคยกันในวิชาวิเคราะห์และออกแบบระบบมันจะคล้ายๆ กับรูปนี้แต่จะต่างกันตรงที่รูปนี้จะเน้นที่ระบบภายนอก
ว่ามีอะไรบ้างที่เกี่ยวข้องกัน , ต้องวิเคราะห์ด้วยว่าระบบแวดล้อม นั้นสามารถรับส่งข้อมูลกันได้จริงหรือเปล่า
เช่น ถ้าต้องการเขียนระบบด้วยภาษา PHP และต้องมีการทำงานร่วมกับภาษา JAVA ซึ่งในบางรูปแบบของการติดต่อกัน
จะเกิดปัญหาเช่นการรับส่งข้อมูลอาร์เรย์ ซึ่งถ้าเราไปวิเคราะห์ไม่ดีและไเขียนโค้ด
PHP เสร็จเรียบร้อยแล้วพอไปใช้งานก็จะติดต่อกันไม่ได้
แต่การเขียน Context Diagram ใน DFD จะเน้นที่ตัว Data กับ Entity นอกระบบเท่านั้น
2. Process Model ( อยู่ในกลุ่ม Behaviour) จะเน้นที่การทำงานของระบบทั้งหมด
มักจะใช้ Data Flow Diagram เขียน

จากรูป <Slide 7> เป็นตัวอย่างของการอธิบาย Process ซึ่งจะเขียนไม่เหมือนกับ
Data Flow ที่เราคุ้นเคย ซึ่งแล้วแต่ตำราแต่ละเล่ม ในรูปจะไม่เน้นที่ Data แต่จะเน้นที่
Process จึงไม่สำคัญที่จะมี Data Store ปรากฎอยู่
ในที่นี้จะมี Entity หลักๆหรือ Data Store จะรวมกับ Entity เข้าไปเลยคือรูปที่เป็นสี่เหลี่ยม
ส่วนในรูปที่เป็นวงรีคือกระบวนการทำงานที่อยู่ในระบบ เส้นปะจะบอกถึงขอบเขตของระบบ
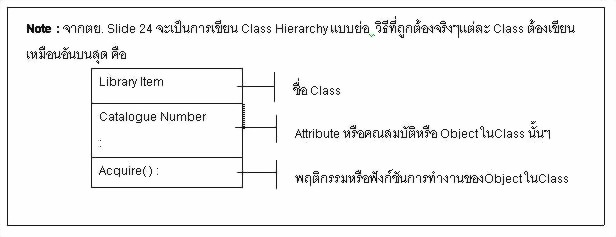
Note :
แต่ในการเขียน Process Model ถึงแม้ว่าเราจะไม่สนใจ Data แต่ถ้าเราไม่ใส่ Data
เข้าไป เราก็จะไม่เข้าใจว่าแต่ละ Process มีความสำคัญอย่างไร ทำหน้าที่อะไร
เพียงแต่ว่า Data Store และ Entity จะรวมเป็นสิ่งเดียวกัน ก็ใช้สัญลักษณ์เป็นสี่เหลี่ยมแทนได้
|
3. Behavioural Model
( อยู่ในกลุ่ม Behaviour ) ใช้อธิบายพฤติกรรมของระบบ แบ่งออกเป็น 2 ลักษณะ
คือ Data Processing กับ State Machine
3.1 Data Processing Model คล้ายๆกับรูป Slide7 คือเน้นที่ DFD เป็นหลัก
แต่จะเน้นที่ขั้นตอนของกระบวนการ เพราะฉะนั้นพอเรามอง DFD เราจะรู้ว่ากระบวนการไหนถูกทำก่อนหรือหลัง
แต่ก็ไม่ใช่ทุกกระบวนการจะต้องถูกกระทำเสมอ
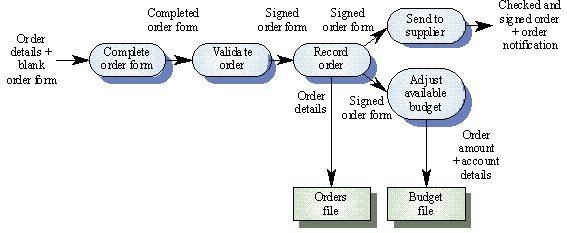
จากรูป <Slide10> เป็นตัวอย่างของการวางใบสั่งซื้อ
(Order) โปรเซสหลักๆจะมี Complete Order Form แล้วจึงไปตรวจสอบใบ Order ว่าถูกต้องหรือไม่
แล้วจึงมีการบันทึกข้อมูลใบ Order แล้วส่งไปยัง Supplier และปรับ Budget ทั้งหมดมี
5 กระบวนการ อย่างน้อยที่สุด DFD ก็จะบอกให้รู้ว่ากระบวนการไหนทำก่อนหลัง อย่างเช่น
เราจะเอารายละเอียด Order ก็ต่อเมื่อผ่านกระบวนการตรวจสอบ Order แล้ว หลังจากการบันทึกใบ
Order แล้วจะเกิดทางแยก 2 ทางคือส่งไปยัง Supplier กับปรับ budget แต่ในบางกรณีอาจเกิดเพียงอยางใดอย่างหนึ่งหรือทั้ง2งานเลย
แต่ถ้ากรณีเป็นลำดับจะหมายถึงทุกเหตุการณ์จะต้องเกิด
Note :
- จะเน้นว่ามีกระบวนการอะไรบ้างในระบบ หรือ SW ที่พัฒนาขึ้นมักจะถูกตัดส่วนออกมาเป็น
Module- เน้นดาต้าว่ามีความสัมพันธ์หรือเกี่ยวพันกับกระบวนการอะไรบ้าง ให้เราประเมินระบบฐานข้อมูลได้ถูกต้อง
, ประเมินขนาด Server , การออกแบบการจัดเก็บข้อมูลได้ถูกต้อง
ยกตย.ใน Slide10 การจัดเก็บ Order
มีการส่ง Order detail มาเขียนลงใน Order File และมีข้อมูลอีกจำนวนหนึ่งถูกส่งไปอีกกระบวนการหนึ่งเพื่อส่งให้
Supplier ตรงนี้เราจะประเมินได้ว่าจะมีข้อมูลอะไรบ้างถูกเอามาเขียน แต่ตย.นี้ไม่มีการอ่านข้อมูลจากไฟล์ให้เห็นซึ่งความจริงการทำงานบางอย่างต้องมีการอ่านจ่ากไฟล์ด้วย
, การเขียนฐานข้อมูล ถ้าเรารู้รายละเอีนดของมันจะช่วยให้เราประเมินได้ว่าฐานข้อมูลควรมีขนาดไหน
บางครั้งฐานข้อมูลเยอะมากแต่อาจเขียนน้อยมาก DBMS จึงมีขนาดไม่ใหญ่มากก็ได้
, ลักษณะการอ่านก็ด้วยว่าเป็นแบบ sequential หรือมีการ Search ที่ไม่ซับซ้อนมาก
DBMS ก็ไม่ต้องใหญ่มาก หรือว่าถ้าเกิดพบว่ามีการเขียนลงฐานข้อมูลเยอะมากเราอาจจะพิจารณาอีกว่าข้อมูลไหนต้องเขียนผ่าน
DBMS ข้อมูลไหนไม่ต้องผ่าน DBMS สามารถเขียนผ่าน File system ได้โดยตรง- ในบางครั้งอาจจะเอาไปอธิบายว่ามีการรับส่งข้อมูลกับระบบอื่นๆที่สภาพแวดล้อมใดได้บ้าง
( ใช้น้อยมาก )
|
3.2 State Machine Models มีมานานแล้วประมาณ
50 ปี แต่ก่อนเป็นที่นิยมในงาน engineer มักใช้อธิบายสถานะที่เปลี่ยนแปลงไปของอุปกรณ์
หรือเครื่องมือที่เขาสร้างขึ้นมา จนมาในระยะหลังเริ่มมีการพัฒนา SW แบบ Object
มากขึ้นก็เลยเกิดวงจรการพัฒนาระบบลักษณะแบบ Object ขึ้นมา ที่เรามักใช้ในปัจจุบันได้แก่
UML ซึ่ง State machine ถูกนำมาใช้มากในระยะหลังก็เพราะ UML นั่นเอง UML ผนวกเอา
State machine เข้าไปเป็นส่วนหนึ่งในการนำเสนอ Behavior ของระบบ
State machine ก็ใช้อธิบายพฤติกรรม
, ลักษณะการทำงานของระบบ ดูตย.จาก Slide 14 จะประกอบด้วยสถานะแต่ละสถานะหรือ state
( เป็นรูปสี่เหลี่ยมมน ) และก็เส้นที่ขีดเป็นการกระตุ้นทำให้เกิดการเปลี่ยนแปลงสถานะ
เรียกว่า Stimuli เพราะฉะนั้นเราก็จะเขียนสถานะของระบบเราขึ้นม าแล้วแต่ว่าระบบเราออกแบบมาให้มีลักษณะไหนได้บ้าง
และบอกว่าแต่ละสถานะเกิดจากการถูกกระตุ้นโดยอะไรบ้าง เช่น สถานะการเข้าไป Update
ข้อมูลในฐานข้อมูลสิ่งที่เข้ามากระตุ้นคือ การSubmit Form
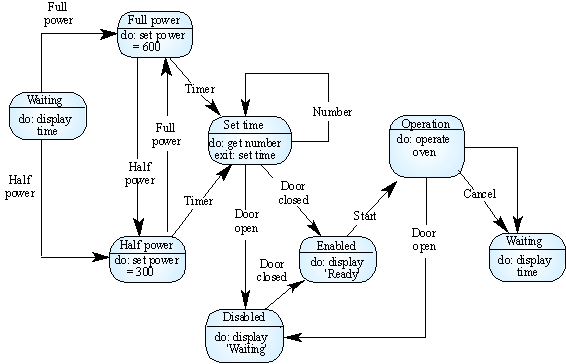
จากรูป <Slide14>
เป็นระบบไมโครเวฟ (ในรูปสี่เหลี่ยมมนอักษรส่วนบนคือชื่อสถานะและส่วนล่างสิ่งที่ต้องทำในเวลานั้น
) สถานะใดเป็นสถานะแรกก็ได้แต่จะเริ่มอธิบายจากสถานะการรอ ( Waiting ) สมมติว่ามีคนกดปุ่ม
Full power ก็จะมีการกระตุ้นระบบให้ใช้กำลังเต็มที่ 600 วัตต์แต่ถ้ากดปุ้ม Half
power ก็จะเกิดการกระตุ้น ณ สถานะนี้ให้เปลี่ยนไปใช้ไฟที่ 300 วัตต์ และในขณะที่เครื่องกำลังทำงานที่
Full power หรือ Half powerถ้า User กดปุ่มตั้งเวลาขึ้นมาก็จะมีการเปลี่ยนสถานะ
เป็นการตั้งเวลา และถ้า user ปิดประตูก็จะมีสถานะเป็น enable ( แสดงข้อความบนจอเป็น
Ready )แต่ถ้าเปิดก็จะเป็น disable ( แสดงข้อความบนจอเป็น Waiting ) และที่สถวนะ
Enable มีการกดปุ่ม Start เครื่องก็จะเริ่มการทำงาน และระหว่างที่ทำงานอยู่ถ้า
user เปิดประตูก็จะปลี่ยนสถวนะเป็น Disable ทันทีเพื่อความปลอดภัยและรอจนกว่าจะมีการปิดประตูและกดปุ่ม
Start ใหม่ หรือถ้ามีการทำงานอยู่และกดปุ่ม Cancel ก็จะเปลี่ยนสถานะไปที่ Waiting
ในอนาคตเราจะวิเคราะห์และออกแบบระบบเป็นแบบ Object ตัว Behaviour ก็จะเป็น method
ใน Object ส่วน Stimuli ก็จะเป็นการส่ง Message ใน Object เพราะฉะนั้น State machine
จึงสอดคล้องกับการพัฒนา SW ในลักษณะ Object มาก
หลังจากเรามีการเขียน State machine แล้ว จะต้องมีการสรุปเป็นเอกสารอ้างอิงที่สำคัญมี
2 อันคือ
1. เอกสารอธิบาย State แต่ละ State ที่เราออกแบบมาทั้งหมดว่าทีรายละเอียดอะไรบ้าง
2. เอกสารอธิบายตัวกระตุ้นว่าลักษณะการกระตุ้นมีอะไรบ้าง , เกิดขึ้นได้อย่างไร
เช่น เครื่องสำรองไฟ ตัวกระตุ้นก็คือ ไฟหยุดจ่าย , ไฟกระชาก , ไฟเกิน , ไฟเดินไม่เรียบ
และการกระตุ้นแต่ละอย่างจะทำให้เกิดการทำงานที่แตกต่างกันด้วย
Note :
เวลาที่เราเขียน State diagram เราจะต้องเขียนทั้งหมด 3 ส่วน
1) ตัว Diagram เพื่ออธิบายระบบของเรา
2) ตารางอธิบายว่า State มีทั้งหมดกี่สถานะ
3) สรุปการกระตุ้นว่ามีทั้งหมดกี่ลักษณะ รายละเอียดคืออะไร
|
3.3 State Chartsในกรณีที่ระบบของเราซับซ้อนมากๆ
State diagram จะไม่สามารถอธิบานรายละเอียดได้มากพอ คือเป็นแค่เห็นภาพรวมของงานทั้งหมด
เราจึงต้องมีการเขียนลงไปถึงรายละเอียดด้วย State chart จาก State diagram ใน Slide14
จะมี State หนึ่งชื่อว่า Operation ซึ่งเราจะใช้อธิบายกับ user และเจ้าของงานได้
มองเห็นภาพรวมได้ แต่ไม่ลึกถึงขนาดเขียนโปรแกรม
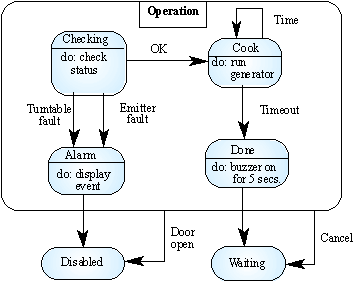
จากรูป <Slide18> เป็นการแตกย่อยของ
State ที่ชื่อ Operation ซึ่งข้างในจะประกอบไปด้วย 4 State และมี Stimuli อะไรบ้าง
ตัวนี้แหละที่เราจะนำไปเขียนโปรแกรม อันแรกเริ่มจากการตรวจสอบที่สถานะ Checking
ว่า Ok จึงเริ่มสร้างความร้อนแล้วก็มีการตรวจสอบเวลา ว่าครบกำหนดเวลาหรือยัง พอครบก็จะเกิด
Stimuli Timeout เปลี่ยนสถานะเป็นส่งเสียงเตือนว่าทำงานเสร็จแล้วและเปลี่ยนสถานะไปสู่การคอยต่อไป
หรือถ้าการตรวจสอบที่ Checking แล้วมีปัญหาก็จะเปลี่ยนสถานะเป็น Alarm หรือถ้ามีปัญหาที่ตัวสร้างความร้อนของไมโครเวฟก็จะ
Alarm อีกลักษณะหนึ่ง หลังจาก Alarm เสร็จก็ Disable ส่วนใน Operation ทั้งหมดไม่ว่าจะทำงานที่
State ไหนก็แล้วแต่ถ้ามีการกดปุ่ม Cancel ก็จะมาที่สถานะ Wait ทันที
เพราะฉะนั้นเส้นที่ลากออกมาจาก State ภายในสู่ State ภายนอกคือ Stimuli ที่เกิดจาก
State ภายในทั้งนั้น แต่เส้นที่ลากจากกรอบใหญ่สู่ภายนอกคือ Stimuli ที่เกิดจากเมื่อไหร่ก็ได้ภายใน
State Operation นี้
Note :
เราจะใช้ State Charts อธิบาย Subsystem หรือ Sub-model |
4.
Semantic Data Modelsอยู่ในกลุ่มของ Structural perspective จะเน้นที่
logical structure ของ data เราเขียนโมเดลนี้เพื่ออธิบายว่ามีข้อมูลอะไรบ้าง มีความสัมพันธ์อะไรบ้าง
Semantic data model ไม่ได้เป็นมาตรฐานใน UML ส่วนใหญ่เวลาเราเขียน UML เราจะใช้
Object Oriented Data Model มาใช้อธิบายใน Data Model
จากตัวอย่างในรูป <Slide20>
จะดูคล้าย E-R diagram ซึ่งจะบอกให้รู้ว่ามี Entity อะไรบ้าง Note : Entity ในที่นี้หมายถึง
Entity ของข้อมูลไม่ใช่ Entity ของระบบ คนละอันกับ DFD เรามักสับสนกันบ่อยๆ เวลาเขียน
DFD 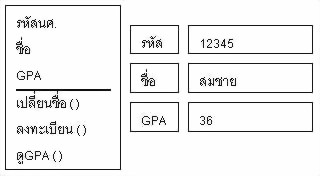 ที่ Context
diagram เราจะมี External entity ซึ่งเป็น คน , สิ่งของหรืออะไรก็ตามที่มีการรับส่งข้อมูลร่วมกันกับระบบของเรา
และลงไปในระดับย่อยก็จะมี Process , Data store , Entity ก็ยังเป็น External Entity
เหมือนกัน
ที่ Context
diagram เราจะมี External entity ซึ่งเป็น คน , สิ่งของหรืออะไรก็ตามที่มีการรับส่งข้อมูลร่วมกันกับระบบของเรา
และลงไปในระดับย่อยก็จะมี Process , Data store , Entity ก็ยังเป็น External Entity
เหมือนกัน
แต่ใน E-R diagram นี้ Entity คือตัว data เลยหมาถึง abstract ของ data แต่ละอัน
ตัวอย่างเช่นข้อมูลของนักศึกษา 3 ชิ้นนี้จับรวมกันจะแสดงถึงนักศึกษา 1 คนเราเรียกว่า
Entity ใน E-R diagram
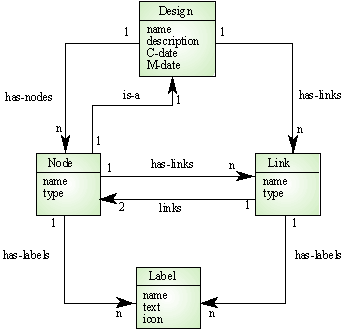
Semantic Diagram Model ใช้อธิบายความสัมพันธ์ระหว่าง
Entity กับ Data Entity จากรูปจะมี Entity Design , Node , Link , Label จะมีอยู่
4 Entity แต่ละ Entity จะมีความสัมพันธ์กันอย่างไรและจะบอกถึงลักษณะความสัมพันธ์ว่าเป็นแบบ
1:1 หรือ 1:M หรือ M:1 ที่แสดงเป็นเส้นขีดแสดงความสัมพันธ์และมีชื่อแสดงความสัมพันธ์บอกเอาไว้
5. Object Model
คือการที่เราอธิบายโปรเจ็คของเราในเชิง Object จะมีอยู่ 3 ลักษณะคือ
5.1 Inheritance models : อธิบายถึงความขึ้นต่อกัน , การสืบทอดกันของ Class
กับ Subclass
5.2 Aggregation models : อธิบายถึง Object หนึ่งประกอบด้วย Object ย่อยๆอะไรบ้าง
5.3 Interaction models : อธิบายว่า Object มีความสัมพันธ์กันอย่างไรบ้าง
5.1 Inharitance modelsคือการที่อธิบายระบบของเราในลักษณะ Object โดยที่เราแบ่งหมวดหมู่ของ
Object ออกเป็น Class และแต่ละ Class ถูกจัดออกเป็นลักษณะลำดับชั้น ( Hierachy
)
The Unified Modeling Language ( UML ) เป็นวิธีการ Model ระบบที่เน้น
Object ล้วนๆ
ลักษณะการเขียน Inharitance Model ใน UML การเขียน UML ในการโมเดลระบบจะต้องอ้างอิง
Object และต้องเขียนเป็น Object Modeling ขึ้นมาในการใช้ UML พัฒนาระบบ
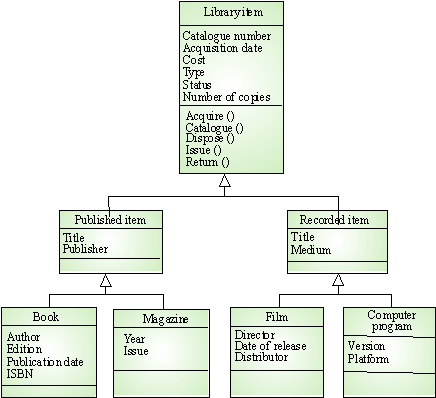
ตย.ระบบห้องสมุด <Slide24>
เราจะวิเคราะห์ว่าโปรเซสและ data มีอะไรบ้าง Data เราจะแบ่งออกเป็นObject ย่อยๆเช่น
มีชื่อหนังสืออยู่ 10 เล่ม ( หรือ 10 Object ) , มีนิตยสารอยู่ 5 เล่ม ( หรือ 5
Object ) , มีวีดีโออยู่ 10 ม้วน ( หรือ 10 Object ) , มีแผ่นComputer Program
10 แผ่น ( หรือ 10 Object ) รวมทั้งหมดเราจะมีเป็น 30 Object ในระบบของเรา ซึ่งเราไม่จำเป็นต้องรู้รายละเอียดว่ามีหนังสือชื่ออะไรอยู่กี่เล่ม
แต่เราจะสนใจความเหมือนกันของข้อมูล หนังสือในห้องสมุดจะมี 100 เล่มหรือ 10 เล่ม
ในฐานข้อมูลก็คือ Entity เดียวกัน ตัวความเหมือนกันของหนังสือรวมเรียกว่าเป็น Class
หนึ่งของหนังสือ และที่นิตยสารจะมีอะไรบ้าง เช่น วันที่ออกรายเดือนหรือรายสัปดาห์
เราก็จับเอาObject ที่มีคุณสมบัติที่เหมือนๆกันจับรวมกันเรียกว่า เป็น Class ของนิตยสาร
เพราะฉะนั้นจากการสำรวจ Object ทั้งหมดจัดเแน Class ได้ 4 Class ได้แก่ Class หนังสือ
, นิตยสาร , หนัง , โปรแกรม แล้วเราก็จะมาดูความเหมือนกัน ที่หนังสือมีการตีพิมพ์และนิตยสารก็มีจึงจับเอา
2 อันนี้มาอยู่ในกลุ่มเดียวกันเรียกว่า Published Item และเราเรียกว่าเป็น Super
Class ของ Class Book และ Magazine ถ้ามองกลับกันเราจะเรียก Class Book และ Class
Magazine ว่าเป็น Subclass ของ Published Item
หนังกับโปรแกรมก็จะมีการบันทึกเหมือนกัน เราก็จับมาสร้าง Class ใหม่เป็น Super
Class คือ Record Item และในห้องสมุดต้องมีการสั่งซื้อ , มีคาตาล็อกให้ค้นหาได้
, มีการยืม-คืน เพราะฉะนั้นจึงมีการสร้าง Class ขึ้นมาอีก Class ชื่อว่า Class
Library Item เป็น Super Class ของ Published Item กับ Record Item
ความสัมพันธ์ระหว่าง Class , Super Class และ Sub Class เราเรียกว่าความสัมพันธ์แบบ
Hierachy ซึ่งบอกถึงคุณสมบัติที่เหมือนกันในส่วนที่แตกต่างกัน คุณสบัติใดๆที่ทุก
Object ทีเหมือนกันหมดจะเอามาไว้รวมกันที่ Super Class เช่น หนังสือกับนิตยสาร
จะมีชื่อสำนักพิมพ์( Publisher )ด้วยกันทั้งคู่ เพราะฉะนั้นสำนักพิมพ์จึงถูกนำมาไว้ใน
Super Class Published Item แต่ว่านิตยสารมีฉบับที่ (Issue)แต่หนังสือไม่มีจึงเอาฉบับที่ไว้ที่ตัว
Class Magazine
วิธีที่อธิบายจากรูปจะเป็นแบบ Bottom Up คือเป็นการบอกว่า Object ทั้งหมดมีอะไรอยู่บ้างและจับกลุ่มแต่ละ
Object มาเป็น Class จับกลุ่ม Class มาเป็น Super Classและจับกลุ่ม Super Class
มาเป็น Super Class ไปเรื่อยๆ
สำหรับระบบที่มีตัวตนอยู่แล้วใช้วิธี Bottom Up จะสะดวกกว่าเพราะมีตัวตนให้อธิบาย
แต่ถ้าบางระบบยังไม่มีตัวตนเลย ยังไม่เคยทำมาก่อน บางครั้งก็ใช้วิธี Top down โดยเริ่มจากเราจะดูว่าเราจะพัฒนาระบบให้ทำอะไรแล้วจึงคิดต่อว่าควรให้แตกย่อยเป็นกลุ่มอะไรบ้าง
คิด Super Class ก่อนแล้วจึงแตกย่อยเป็น Sub Class
Encapsulation
การที่ข้อมูลใน Objectจากโลกภายนอกไม่ได้เลย
ถ้าจะเปลี่ยนแปลงต้องเปลี่ยนด้วยตัวของมันเอง เช่น นศ.มีชื่ออยู่และต้องการเปลี่ยนชื่อนศ.
จะเปลี่ยนโดยตรงไม่ได้ จะต้องเปลี่ยนโดยใช้ Method ชื่อว่า เปลี่ยนชื่อ( ) ให้ทำการเปลี่ยนให้หรือถ้าอยากดูข้อมูล
GPA จะดูโดยตรงไม่ได้ต้องเรียก Method ที่ชื่อว่า ดูGPA( )
เพราะฉะนั้นการที่เราออกแบบระบบของเราเป็นแบบ Object มันจะมีข้อดีคือ ส่วนบนจะนำไปเป็นฐานข้อมูล
และส่วนล่างนำไปเขียนโปรแกรมเป็นฟังก์ชันการทำงาน
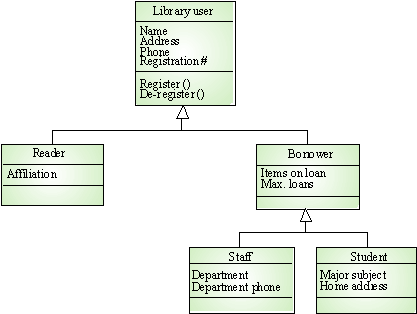
จากรูป <Slide25> เป็นตย.ของ Class
Hierachy กรณีของ user ผู้ใช้ห้องสมุดทั้งหมดแบ่งออกได้เป็นกลุ่มคนที่เข้ามาค้นหาเฉยๆ
กับกลุ่มคนที่เข้ามายืม ทั้ง2มีความแตกต่างกันคือ กลุ่มที่เข้ามายืมจะสนใจในเรื่องของจำนวนการยืม
, วันที่ยืม และในส่วนของผู้เข้ามายืมเราแบ่งออกเป็น 2 กลุ่มคือ Staff กับนศ. Staff
อาจจะยืมได้เดือนนึง นศ.อาจจะยืมได้ 2 เดือน มีความแตกต่างกันในเรื่องการยืม ,
ที่อยู่ติดต่อ
เพราะฉะนั้นตัวอย่างนี้จะเป็นแบบ Top-Down คือแบ่งจากกลุ่มใหญ่มากลุ่มย่อย จากกลุ่มย่อยแบ่งเป็นกลุ่มย่อยลงไปอีก
ปัญหาที่เกิดขึ้นจากการเขียน Class Hierachy ถ้าสังเกตุดีๆจะพบว่า Class
Hierachy มันจะมีความสัมพันธ์ระหว่าง Super Class แบบ 1:M แต่ในทางปฏิบัติอาจเกิดกรณีนี้ขึ้นคือ
Sub Class ไปอ้างอิงกับ 2 Super Class เป็นแบบ M:1 เรียกว่า Multiple Inheritance
หมายความว่า Object ที่อยู่ใน Sub Class ได้รับการถ่ายทอดมาจาก 2 Super Class และ
2 Super Class นี้ไม่มีอะไรซ้ำกันเลย Sub classก็จะรับ attribute ทั้งหมดของทั้ง2
Super class ลงมา
 แต่ถ้าบังเอิญว่า
2 super class นี้มี Attribute ที่ซ้ำกันอยู่ ปัญหาจึงเกิดขึ้นมาว่าเมื่อมีการถ่ายทอดคณสมบัติลงมายังตัว
sub class มันจะเลือก attribute จาก super class ไหน
แต่ถ้าบังเอิญว่า
2 super class นี้มี Attribute ที่ซ้ำกันอยู่ ปัญหาจึงเกิดขึ้นมาว่าเมื่อมีการถ่ายทอดคณสมบัติลงมายังตัว
sub class มันจะเลือก attribute จาก super class ไหน
วิธีแก้ปัญหากรณีแบบนี้เกิดขึ้นจะมีอยู่
3 แบบคือ
1) เมื่อเกิดเหตุการณ์แบบนี้แล้วจะทำการ Reject ไม่ยอมรับการทำงานต่อเลย
เหมาะกับระบบที่เป็น Formal specification คือผิดพลาดไม่ได้เลย
2) ระบบมีการถามว่ามี multiple inheritance จาก super class ตัวใดและให้ user เลือกว่าจะใช้ของตัวไหน
วิธีนี้จะดีก็ต่อเมื่อ user เป็นผู้ที่เข้าใจระบบและสามารถตัดสินใจได
้3) Set default ค่า Priority ไว้ว่าถ้าเกิดเหตุการณ์นี้แล้วจะเลือก super class
ที่มี Priority สูงกว่ามาใช้ วิธีนี้จะเหมาะเมื่อ user ไม่มีความเข้าใจในระบบและไม่สามารถตัดสินใจได้
Note :
ความสัมพันธ์ใน Hierachy Model จะเรียกว่า is-a relationship จากรูป25เวลาอ่านจะอ่านว่า
Reader is-a Library user ( ผู้อ่านเป็นผู้ใช้ห้องสมุดประเภทหนึ่ง ) , Staff
is-a Borrower ( Staff เป็นผู้ยืมประเภทหนึ่ง |
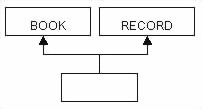
5.2 Agregation Model เป็นการอธิบายในเชิง
Collection เป็นการอธิบายว่า Object หนึ่งๆเกิดมาจาก Object ย่อยอะไรประกอบกันบ้าง
ความสัมพันธ์ในแบบ Aggregation model มักจะเป็นแบบ Part-of relationship

จากรูป <Slide28> Class ที่อยู่บนสุด
Study pack จะประกอบด้วย Object ย่อยๆ 4 Object คือ Assignment , OHP Slide , Lecture
Notes และ Videotape มารวมกัน ลักษณะอย่างนี้เรียกว่าความสัมพันธ์แบบ Part-of เวลาเราอ่านจะอ่านว่า
Assignment เป็นส่วนหนึ่งของ Study pack หมายถึง Assignment ไม่ได้เป็น Sub class
ของ Study pack แต่เป็นส่วนนึ่งของ Study pack ไม่ได้ขึ้นต่อกันหรือมีคุณสมบัติสืบทอดที่เหมือนกัน
Behaviour Modeling จะใช้มากใน
UML เป็น Model ชนิดอธิบายพฤติกรรมของระบบ โดยจะใช้แผนภูมิชื่อว่า User-case ในการอธิบาย
ดังตย.ใน slide30 การเขียน use-case เราจะระบุ Object ต่างๆในระบบของเราแล้วก็จะระบุผู้ที่เกี่ยวข้องกับระบบ
อาจจะเป็น user หรือระบบอื่นที่อยู่ภายนอกระบบเราก็ได้ หรืออาจจะเป็น Envirpnment
ต่างๆก็ได้
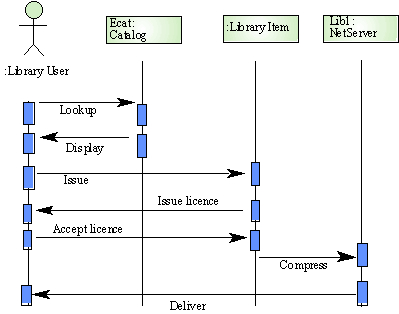
อธิบายรูป
เราจะมี user ผู้ใช้ห้องสมุด 1 กลุ่ม และอีก 3 Object คือ Catalog , Library
Item และ Net Server
ลักษณะการเขียนของ use-case จะบอกถึงลำดับความสำคัญ โดยแต่ละกล่องสี่เหลี่ยมจะเน้นที่ลำดับเหตุการณ์ที่เกิดขึ้น
เกิดที่ Object ไหน ต่อเนื่องไปยังไงบ้าง
ลำดับเหตุการณ์ที่เกิดขึ้น
- เหตุการณ์แรกเกิดจาก user จะ search หาข้อมูลซึ่งจะไปกระทำที่ Object Catalog
- ผลลัพธ์ที่ได้เกิดจาก Object Catalog ส่งกลับไปให้ user
- หลังจาก user เห็นผลลัพธ์แล้ว เขาก็จะระบุเล่มที่เขาต้องการไปยัง Object Library
Item
- Object Library ก็จะส่ง Compress เนื้อหานั้นส่งไปยัง Object Net server
- Net Server ก็จะส่งสิ่งที่ถูก Compress กลับมายัง user อีกที
นี่คือ interactive ที่เกิดขึ้นระหว่าง
user กับ entity นอกระบบที่เกี่ยวข้องกับระบบ มันเข้ามาทำงานกับ Object ไหนบ้างในระบบและลำดับการทำงานเป็นอย่างไร
ในการเข้ามาเกี่ยวข้องกับ Object แต่ละ Object ในลักษณะไหน มีการอ่าน-เขียนข้อมูลไหม
เพราะฉะนั้นตรงนี้ จะบอกรายละเอียดได้ค่อนข้างมากในแง่ของการใช้งานจริง
ปกติเวลาเราวิเคราะห์ออกแบบระบบเราจะเขียน DFD , E-R diagram เราจะเห็นโครงสร้างของระบบชัดเจน
แต่เราไม่เห็น Interaction ที่เกิดขึ้นจริงๆของระบบ แต่ถ้าเราใช้ use-case , state
machine หรือ UML เราจะเห็น Interaction เพรสะฉะนั้น Use-case เป็นสิ่งสำคัญอีกอย่างหนึ่งที่ควรจะเขียนได้
อ่านหรือตีความได้
บรรยายเมื่อ 21 ธค. 2544 เทอม 2/44
ทวนเรื่อง Client – Server
จุดสำคัญอยู่ที่หน้า 14 application
ใดๆก็ตามที่เราออกแบบมาจะต้องแบ่งได้เป็น 3 ส่วนเสมอ
1. Presentation Layer - เน้นในเรื่องการแสดงผล , การรับข้อมูล
2. Application Layer – ทำหน้าที่ประมวลผล และวิเคราะห์ข้อมูล
3. Data management Layer - ทำหน้าที่ติดต่อกับข้อมูลClient – Server Architecture
จะเป็นการตัด application ออกเป็นส่วน และเลือกว่าจะอาส่วนไหนไปไว้ใน client ส่วนไหนไปไว้ใน
Server ถ้าเอาส่วน Presentation ส่วนเดียวไปไว้ที่ Client เราเรียกว่าเป็น Thin
– client บางระบบเอา Presentation layer กับ Application layer ไปไว้ที่ Client
อันนี้เรียกว่าเป็น Fat – Client บางระบบ Application layer มันใหญ่มากเราก็จะมีการแบ่งออกเป็น
2 ส่วนอีก ส่วนหนึ่งเอาไปไว้ที่ Client อีกส่วนก็เอาไปไว้ที่Server ก็ได้ เพราะฉะนั้นรูปแบบต่างๆอาจจะแบ่งได้เป็นดังนี้
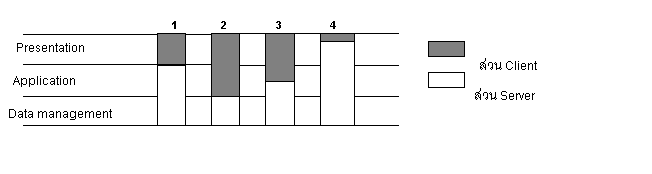
- ส่วนใหญ่แล้ว Client จะไม่ยุ่งกับส่วน
Data Management Layer
- งานส่วนใหญ่ที่เป็น web application จะตกอยู่ในส่วนของ 1 กับ 4
- ส่วนงาน Application ที่เป็นประเภท stand alone หรือ network จะอยู่ในกลุ่มของ
2 กับ 3
เพราะฉะนั้นในฐานะของผู้พัฒนา
Application เราควรจะพิจารณาว่าเราควรจะวาง layer ไหนไว้ที่ Client –Server ไหน
พิจารณาได้จากหลายปัจจัย ปัจจัยหนึ่งก็คือลักษณะการประมวลผลของตัว layer application
ว่าทำงานหนักเกินไปหรือเปล่าต้องให้ฝั่ง client ช่วยหรือไม่ หรือว่าลักษณะการนำเสนอข้อมูล
presentation layer รับผิดชอบเพียงฝ่ายเดียวได้หรือไม่ และรวมถึงระบบเครือข่ายด้วยว่าเหมาะสมหรือไม่
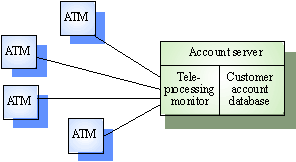
จากตย. <slide20> เป็นระบบ ATM ซึ่งเป็นแบบ
Thin – Client ตัวที่เป็น ATM ทางด้านซ้ายมือคือ Application Layer หรือ business
logic ทางด้านขวาก็เป็นตัวติดต่อ Data management แต่ทั้งหมดอยู่บน server ส่วนฝั่ง
Client ก็รับผิดชอบเรื่องการแสดงผลอย่างเดียว
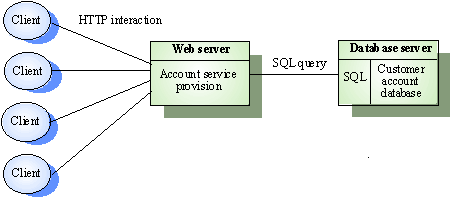
Three – Tier – Architecture
คือการที่เราแบ่งทั้ง 3 layer ออกเป็น 3 ส่วนเลย ส่วนของ Presentation จะเอาไปไว้ที่
Client ส่วนของ Application จะเอาไปไว้ที่ server ตัวหนึ่ง และส่วน Data management
จะเอาไปไว้ที่ Server อีกตัวหนึ่งตัวอย่างการแบ่งจะเป็นดังรูปข้างล่าง (slide22)

web application ส่วนใหญ่จะเป็นแบบ 3 - tierคือฝั่ง
Client เป็น browser ที่ผู้ใช้ใช้งาน ส่วนฝั่ง server น้อยสุดก็จะมี 2 ตัวคือ ตัวหนึ่งทำหน้าที่เป็น
web server ซึ่งขึ้นอยู่กับว่าเครื่องที่เป็น Hardware ที่ใช้เป็น Server มีประสิทธิภาพสูงแค่ไหน
ถ้าสูงพอเขาก็จะรวมเอา web server กับ application server มาไว้ในตัวเดียวกัน ส่วนอีกตัวหนึ่งทำหน้าที่เป็น
database server ซึ่งจะถูกแยกออกมาเป็นอีกหนึ่งตัวอยู่แล้ว แต่ถ้าบางระบบมี application
ที่ใหญ่มาก web server รับผิดชอบงานส่วน application ไม่ไหว เขาก็จะแบ่งออกเป็นอีก
server หนึ่งกลายเป็น 4 – tier
หรือในบางระบบที่มีขนาดใหญ่มากก็จะมีการทำเป็น
Clustering ก็คือการที่ฝั่ง Browser ต่อผ่าน Internet มาถึงฝั่ง web server และตัว
web server ก็จะมีการแตกออกเป็นหลายๆตัวอีก เช่น เว็บไซท์ Yahoo , Microsoft และ
Web server แต่ละตัวก็จะติดต่อกับ application layer เป็นกลุ่มๆอีก แต่ละ Application
Server ก็จะแบ่งหน้าที่กันไป และ Database server ก็มักจะต่อตรงเข้ากับ Database
แต่ละตัวโดยตรง ดังรูป
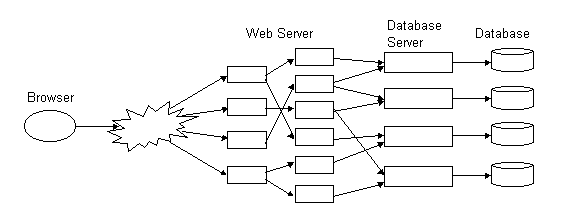
ลักษณะนี้เรียกว่า Clustering เพราะว่าในหนึ่งกระบวนการทำงานจะถูกจัดโดยกลุ่มๆหนึ่ง
เรียกว่าเป็น Multi –Tier จากรูปข้างล่าง (Slide23) เป็นระบบ ATM แต่ผ่านทาง internet
โดยจะแบ่ง web server และ DB server เป็น 3-tier
ตารางข้างล่าง (Slide24)จะบอกว่าปัจจัยในการตัดสินใจว่าควรจะใช้กี่
tier จึงจะเหมาะสม
|
Architecture
|
Applications
|
|
Two-tier C/S architecture with thin
clients
|
Legacy system applications where separating
application processing and data management is impractical
Computationally-intensive applications
such as compilers with little or no data management
Data-intensive applications
(browsing and querying) with little or no application processing.
|
|
Two-tier C/S architecture with fat
clients
|
Applications where application processing
is provided by COTS (e.g. Microsoft Excel) on the client
Applications where computationally-intensive
processing of data (e.g. data visualisation) is required.
Applications with relatively
stable end-user functionality used in an environment with well-established
system management
|
|
Three-tier or multi-tier C/S architecture
|
Large scale applications with hundreds
or thousands of clients
Applications where both the
data and the application are volatile.
Applications where data from
multiple sources are integrated
|
Distrubuted Object
Architecture
เป็นแนวคิดใหม่ เพิ่งมีมาไม่นานมาประมาณ 5-6 ปี เป็นแนวคิดที่ server มีหน้าที่ให้บริการ
ส่วน client ร้องขอบริการ และจะมองว่า Object ใดๆก็ตามที่อยู่บนระบบเครือข่ายหรือบน
Application จะถูกเปรียบว่ามันคือ Object และตัวมันเองก็สามารถทำหน้าที่ให้บริการได้
เพราะฉะนั้นทุก Object สามารถให้บริการได้หมด ขึ้นอยู่กับว่า ณ ขณะนั้น Application
ต้องการใช้บริการอะไรมันก็จะไปร้องขอบริการจาก Object นั้นๆ
มันก็คือเป็นการเปลี่ยนจากฝ่ายหนึ่งทำหน้าที่อย่างใดอย่างหนึ่งไม่ว่าจะเป็นให้บริการหรือใช้บริการกลายเป็นทุกๆส่วนของ
Application สามารถมีบทบาทในการให้บริการทั้งนั้น แต่เราก็ต้องรู้ว่าใครจะให้บริการได้บ้าง
เราถึงจะไปร้องขอบริการได้ถูกต้อง
การร้องขอบริการระหว่าง Object ด้วยกันเองในระบบมันจะเป็นการร้องขอผ่าน
Bus ซึ่ง Busใน Hardware อาจจะเห็นได้ชัดกว่า Bus ใน Software ที่ไม่มีตัวตน
เพราะ Bus ใน Software เป็นการเขียนโปรแกรมร้องขอหรือเรียกใช้ฟังก์ชันจาก Object
อื่นๆผ่านระบบเครือข่าย เรียกว่า Object Request Broker ( ORB ) พราะฉะนั้น
Object ต่างๆก็จะติดต่อผ่านทาง ORB เพื่อร้องขอบริการจาก Object อื่นๆ
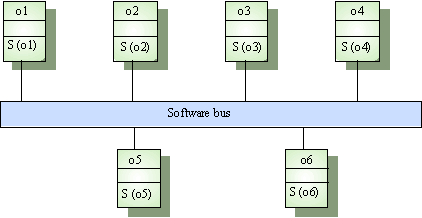
จากรูปข้างบน (slide26) จะมีตย. Object
อยู่ 6 Object แต่ละObjectก็จะมี service ของตัวเอง และทั้งหมดติดต่อกันผ่านทาง
Bus ถ้า Application กำลังรันอยู่และมีการเรียกใช้ Object เบอร์ 5 แล้วบังเอิญObjectเบอร์5ก็ต้องการบริการบางอย่างจาก
Object เบอร์3 Objectเบอร์5ก็จะร้องขอบริการ Object เบอร์3ผ่านทาง Bus
เพราะฉะนั้นทั้งหมดจะมีฐานะเท่ากันหมดไม่มีใครเป็น
Client-Server เราจึงอาจจะเปรียบ Distributed Object Architecture ว่าเป็นลักษณะแบบ
Peer-to-Peer ก็ได้ ( Peer-to-Peer คือทุก Object ในระบบมีความเท่าเทียมกันต่างก็สามารถร้องขอและให้บริการได้ด้วยกันทั้งนั้น
)
ข้อดี
1. เนื่องจากว่ามันไม่มีการกำหนดว่าใครจะเป็นผู้ร้องขอและให้บริการตั้งแต่ต้น
เพราะฉะนั้นผู้พัฒนาระบบไม่จำเป็นต้องกำหนดตั้งแต่แรกว่าการให้บริการแต่ละบริการจะต้องมี
server ตัวไหนเป็นผู้ให้บริการ ไม่ต้องกำหนด Spec. ของตัว Server คือออกแบบในลักษณะ
Logic ไปได้เลยว่าใครให้บริการอะไรบ้าง
2.เป็นระบบที่ยืดหยุ่น เราสามารถจะเพิ่ม Object , การให้บริการ , ปรับเปลี่ยนอะไรเมื่อไหร่ก็ได้เพราะว่าเป็นการเพิ่ม
Object เข้าไปในระบบเท่านั้นเอง ส่วนใหญ่แล้ว Object ที่เพิ่มเข้าไปในระบบมักจะอยู่ในรูปของ
Library พอเพิ่ม Object หนึ่ง Object ก็ไปเพิ่มข้อมูลใน Library พอเรามี Library
ใช้ในการอ้างอิงเวลาเราเขียนโปรแกรมจะสามารถร้องขอบริการจาก Object ต่างๆได้สะดวกขึ้น
CORBA
เป็นการ implement ของ Distributed object ลักษณะหนึ่ง ซึ่งปัจจุบันมีอยู่
2 ค่ายที่พัฒนาขึ้นมาใช้คือ ขององค์กรที่ชื่อว่า Object Management Group (OMG)
ซึ่งได้พยายามกำหนดมาตรฐานการร้องขอบริการระหว่าง Object ให้เป็นมาตรฐานกลางขึ้นมาให้ทุกคนได้ใช้เป็นระบบเปิด
กับของอีกค่ายหนึ่งคือของ Microsoft ที่กำหนดมาตรฐานขึ้นมาใช้งานลักษณะเป็น Distributed
Object เหมือนกันแต่เรียกว่า DCOM
เนื้อหาส่วนนี้ไม่ค่อยเกี่ยวกับ Software engineering เท่าไหร่ เพียงแต่แนะนำให้รู้จักเอาไว้เท่านั้น
บรรยายเมื่อ 18 กพ. 2545 เทอม 2/44